
Le silence de Fred
Paris, Décembre 2013
Il y a bien longtemps, lorsque les fées se sont penchées sur le berceau des différents métiers, elles sont finalement arrivées sur celui du scientifique. Elles se sont placées en cercle autour, puis la première a déclaré : « Tu auras la faculté de comprendre le Tableau de Mendeleïev », puis elle toucha le scientifique au front d’un coup de baguette magique et s’en alla.
La seconde s’approcha et dit « tu seras capable de résoudre certaines grandes énigmes du vivant », puis elle disparut à son tour.
Arriva enfin la troisième fée. Elle était très laide, avec un gros bouton poilu sur le nez et n’aimait pas les chats.
Elle dit « Tu gagneras une misère toute ta vie et, même si tu changes la destinée de millions de tes contemporains, tu resteras inconnu du grand public et mourras dans l’indifférence générale ».
Puis elle s’envola sur son balai, dans un grand rire sardonique.

Le 19 novembre dernier est mort à Cambridge (et à 95 ans) Frederick Sanger.
Ami lecteur, n’ai pas honte.
En ces temps où, pour accéder à la célébrité, il est préférable d’être candidate mammairement hypertrophiée d’émission de télé réalité, ou footballeur analphabète et arrogant, voire chanteur de bluettes approximatives, il est somme toute logique que ce nom ne te dise rien.
Pourtant, j’aimerais, ami, que tu consacres quelques minutes de ton temps -que j’imagine précieux- à avoir une pensée (ou à boire un coup, ou à prier, selon les dieux que tu honores) à la mémoire de celui qui fut probablement l’un des plus grands scientifiques du XXème siècle. Le genre de personne qui a changé notre vie à jamais et qui, de plus, était un vrai grand honnête homme.
Né en 1918, dans le riant comté du Gloucestershire au Royaume Uni, il est le fils d’un médecin généraliste quaker et d’une héritière de l’industrie cotonnière. Profondément pacifiste, il décide, lorsque la Grande Bretagne entre en guerre en 1939, d’opter pour le statut d’objecteur de conscience.
Après avoir obtenu son doctorat en 1943, il commence à travailler dans le département de Biochimie de l’université de Cambridge, dans lequel il passera ensuite l’essentiel de sa vie à travailler sur deux grands types de molécules du vivant (ce qu’on appelle les biomolécules) : les protéines et les acides nucléiques. Il obtiendra (fait rarissime) deux prix Nobel de chimie (en 1958 et en 1980) en récompense de ses travaux.
Dans une cellule, et pour simplifier, on peut trouver quatre grandes familles de molécules :
- Les lipides : c’est la matière grasse. Ils constituent les parois de cellules et servent aussi de stockage pour l’énergie produite par le métabolisme (pas très intéressants).
- Les glucides : Plus communément appelés les sucres. Une autre forme de carburant pour la cellule ; à part servir à apporter de l’énergie, pas passionnants non plus.
- Les peptides et protéines (c’est la même chose : un peptide est une petite protéine… ou une protéine est un grand peptide).
- Les acides nucléiques.
Ces deux dernières molécules (bon, n’écoutez pas, les lipides et les glucides) sont les molécules « intelligentes » de la cellule :
Les acides nucléiques (dont le plus connu, l’ADN ou acide désoxyribonucléique) renferment l’information sur ce que doit faire la cellule.
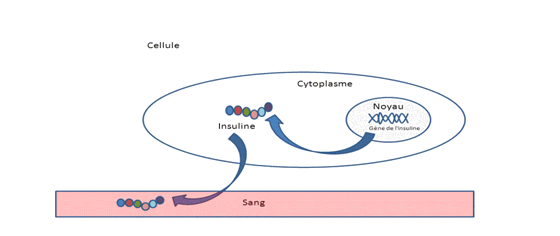
Par exemple, une cellule de la peau contient le programme nécessaire pour fabriquer l’hormone mélanotrope qui va stimuler la synthèse de la mélanine, responsable du bronzage. Une cellule de pancréas, elle, contiendra l’information nécessaire à la synthèse de l’insuline. Chacun son boulot. Vous n’avez jamais vu un pancréas bronzer, non ?
Ce programme spécifique se présente sous la forme d’un petit morceau d’ADN, localisé dans le noyau de la cellule – d’où le nom d’acide nucléique- que l’on appelle un gène.
Ce petit bout d’ADN sera ensuite lu par la machinerie cellulaire et « traduit » en peptide (ou en protéine) qui sera chargé de faire le boulot : par exemple le gène de l’insuline (situé dans le noyau de certaines cellules de pancréas) sera traduit en insuline (le peptide) dont le travail sera de réguler le taux de glucose dans le sang.
Pour faire simple, disons que les acides nucléiques sont la tête et les peptides/protéines les jambes !
Exemple pour une cellule de pancréas synthétisant de l’insuline :
Pour réaliser tous les gènes et toutes les protéines existantes, la nature a simplement besoin de deux alphabets :
- Un alphabet a quatre lettres : A, C, G, T pour l’ADN. Chacune des lettres est appelée « base »
- Un alphabet a 20 lettres pour les protéines. Chacune des lettres est appelée « acide aminé »
Ces alphabets existent depuis la création de la première cellule vivante (à peu près), mais pendant très longtemps, les scientifiques ne savaient pas les « lire ».
Fred Sanger s’est tout d’abord intéressé aux peptides.
Il affirme que les peptides et les protéines sont constitués d’un enchainement d’acides aminés (un peu comme un collier qui serait composé de perles différentes) et le prouve : Il est le premier à inventer une méthode de lecture (on dit séquençage chez les biochimistes) des peptides, puis, dans la foulée, à utiliser sa technique afin d’établir la séquence de l’insuline, qui fut donc le premier peptide séquencé.
Il confirmait ainsi les travaux de Fischer sur la structure des protéines (un autre prix Nobel, lui en 1902) effectués dans les années 1900. Pas si évident que cela à une époque où certains pensaient encore que les protéines étaient des structures amorphes, sans structure bien définie.
Il découvrit donc la structure de l’insuline, composé de deux chaines reliées entre elles :
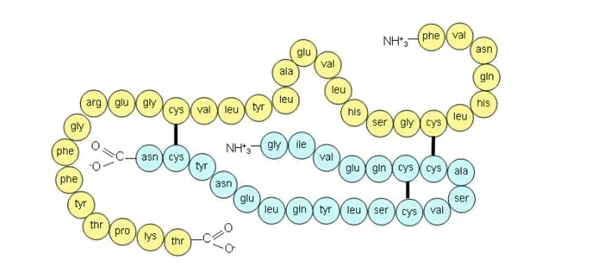
L’enchaînement des acides aminés, qui définit le peptide ou la protéine, est appelé la séquence. Séquencer un peptide (ou une protéine), c’est déterminer la nature des acides aminés qui entrent dans sa composition et l’ordre de ceux-ci. Dans le cas de l’insuline, Sanger a déterminé par exemple que l’enchainement des acides aminés (voir en haut à droite du schéma) était Phe-Val-Asn-Gln … etc pour une chaîne et de Gly-Ile-Val-Glu… etc pour l’autre.
Bon là, c’est simple mais imaginez une protéine, genre Hémoglobine, qui est composée de 574 acides aminés, ou encore la plus grosse protéine connue chez l’être humain, qui est composée de 30 000 acides aminés et qui s’appelle…. la Titine (authentique !).
Personnellement, je cherche toujours après…
« Cé bien beau tout ça, mais a koikçasert, » auriez-vous beau jeu de me rétorquer ?
Et bien puisqu’on savait, grâce à Sanger, quel était l’enchainement des acides aminés, on a pu, dès le début des années 60, fabriquer de l’insuline synthétique (cela c’est fait simultanément dans les laboratoires de l’université de Pittsburgh, aux Etats-Unis et de l’université de Aachen – ou Aix la Chapelle- en Allemagne). Cette insuline synthétique -et donc pure - a permis de soigner des malades du diabète qui étaient auparavant traités avec des extraits de pancréas de veau, de bœuf ou même de chien. Ces préparations étaient souvent impures et entrainaient fréquemment abcès ou réactions allergiques.
Entre 1951 et 1953 les travaux de Sanger établissant la séquence complète de l’insuline furent publiés dans une série de quatre articles dans la revue scientifique « Biochemical Journal » (1).
En 1958, il reçut le prix Nobel de chimie pour « ses travaux sur la structure des protéines et spécialement sur celle de l’insuline ». A l’issue de la cérémonie, juste après que le roi de Suède lui eut remis le prix, il déclara : « C’est le genre de truc qui ne vous arrive qu’une fois dans la vie !!! » (2)
Et ben non.
Parce qu’ensuite, il s’est intéressé à l’autre groupe de molécules « intelligentes » : les acides nucléiques, et plus particulièrement à l’acide désoxyribonucléique, ou ADN.
Ici, je vous le rappelle, l’alphabet est encore plus simple, car constitué de quatre lettres uniquement.
Les « lettres » A, C, G, et T sont appelées les bases. Un gène (c'est-à-dire un bout d’ADN contenant l’information nécessaire à la synthèse d’un peptide ou d’une protéine) moyen a une longueur de 30 000 bases. (Mais la longueur peut aller de quelques centaines à 2,4 millions de bases). Ces bases sont groupées par paquet de trois, qu’on appelle un codon : par exemple pour le gène de l’insuline 333 bases sont groupées en 111 codons :

C’est en lisant ces séries de codes en trois lettres que la cellule sait ce qu’elle doit fabriquer (ici, de l’insuline) : Si on séquence l’intégralité de l’ADN d’une cellule, on sait presque tout d’elle.
C’est de nouveau Fred Sanger qui a le premier inventé une technique permettant de séquencer l’ADN. L’article décrivant sa découverte fut publié en 1977(3). Son second prix Nobel lui fut décerné en 1980 « pour sa contribution à la détermination de la séquence en bases des acides nucléiques ».
Grâce à sa technique, les chercheurs du monde entier commencèrent aussitôt à séquencer les ADN de nombreux organismes : très rapidement, la totalité de l’ADN (le génome) d’une bactérie fut séquencé (1995) puis, moins de vingt ans après la découverte de Fred, le 14 avril 2003, le séquençage du génome humain soit trois milliards de bases, fut déclaré terminé, bien en avance sur les prévisions les plus optimistes.
Ce séquençage du génome humain est sans doute l’une des découvertes les plus importantes du XXème siècle, car elle permet de lire, et donc de comprendre, l’intégralité du « programme » d’un être humain. Grâce à ces travaux, on sait déjà, par exemple, rechercher des mutations dans certaines régions de l’ADN humain permettant la création de test de dépistage de la prédisposition au cancer du sein chez la femme (basé sur l'identification de mutations dans deux gènes humains appelés BRCA1 et BRCA2).
On voit déjà se dessiner un avenir proche où chacun d’entre nous, pourra faire séquencer son propre ADN, et ainsi connaitre toutes ses prédispositions et résistances aux maladies …Chacun pourra ainsi bientôt être soigné de manière ciblée avec des médicaments adaptés.
C’est ce qu’on appelle la « thérapie génique »… Soigner en corrigeant les gènes défectueux que nous a donnés la nature. Non plus pallier les effets négatifs de notre destinée, mais la changer…
Donc notre ami Fred était un génie, n’ayons pas peur des mots. Il a été le premier à inventer le moyen de décrypter deux types de molécules essentielles au vivant : les peptides et l’ADN. On a pu dire de lui qu’ « il était l’un des scientifiques les plus importants du XXème siècle, qui avait changé par deux fois la direction du monde scientifique »(4).
Athée convaincu (« je voudrais bien croire en Dieu, mais c’est vraiment trop difficile. Je manque de preuves »(5)), commandeur de l’Ordre de l’Empire Britannique (1963) et de l’Ordre du Mérite(1986), il était d’une modestie et d’une discrétion rare : lorsqu’on lui proposa de l’anoblir, il répondit : « Je n’ai pas vraiment envie qu’on m’appelle « Sir » et puis, devenir Chevalier doit vous rendre différent… et je ne tiens pas à être différent ».
Malgré ses découvertes qui avaient changé le monde, il continuait de se définir simplement comme « Juste un mec qui trifouillait dans un labo » (Just a chap who messed about in a lab) …
Pacifiste, athée, modeste, discret, et amoureux de ses roses à la retraite, celui que tout le monde appelait Fred restera surtout quelqu’un grâce à qui notre connaissance du vivant a fait un pas gigantesque en avant…
Au revoir, Monsieur Sanger...
“Of the three main activities involved in scientific research, thinking, talking and doing, I much prefer the last and am probably best at it. I am all right at the thinking, but not much good at the talking.”
Des trois activités qui sont impliquées dans la recherche scientifique (penser, parler et faire), je préfère de beaucoup la dernière, et c’est aussi probablement ce que je fais le mieux. Je sais aussi à peu près penser, mais ne suis vraiment pas très doué pour parler.
Frederick Sanger, (Annu. Rev. Biochem., 1988, 57, 1)
BIBLIOGRAPHIE
1 : Sanger, F.; Tuppy, H. (1951a), "The amino-acid sequence in the phenylalanyl chain of insulin. 1. The identification of lower peptides from partial hydrolysates", Biochemical Journal 49 (4): 463–481, PMC 1197535, PMID 14886310.
Sanger, F.; Tuppy, H. (1951b), "The amino-acid sequence in the phenylalanyl chain of insulin. 2. The investigation of peptides from enzymic hydrolysates", Biochemical Journal 49 (4): 481–490, PMC 1197536, PMID 14886311.
Sanger, F.; Thompson, E.O.P. (1953a), "The amino-acid sequence in the glycyl chain of insulin. 1. The identification of lower peptides from partial hydrolysates", Biochemical Journal 53 (3): 353–366, PMC 1198157, PMID 13032078.
Sanger, F.; Thompson, E.O.P. (1953b), "The amino-acid sequence in the glycyl chain of insulin. 2. The investigation of peptides from enzymic hydrolysates", Biochemical Journal 53 (3): 366–374, PMC 1198158, PMID 13032079.
2 : Time – Obituaries – Frederick Sanger - November 21st 2013
3 : Sanger, F.; Nicklen, S.; Coulson, A.R. (1977), "DNA sequencing with chain-terminating inhibitors", Proceedings of the National Academy of Sciences USA 74 (12): 5463–5467,
4 : J. Craig Venter (@JCVenter) November 20, 2013
5 : Ahuja, Anjana (12 January 2000), "The double Nobel laureate who began the book of life", The Times (London): 40
A découvrir aussi
- Dieu est amour
- Covidgrenier, ou les mots-valises de l'épidémie
- La quadruple imposture : Pour en finir avec l'écologie politique. Deuxième partie
Inscrivez-vous au blog
Soyez prévenu par email des prochaines mises à jour
Rejoignez les 59 autres membres